����֤ȯ�ɷ�����˾��Ϣ�������� ���� ���� ����h ����Ȼ ����
����֤ȯ�ɷ�����˾( ���¼�ơ�����֤ȯ��)
�ڸ���ҵ��չҵ�����У���Ҫ��ʱ��ȷ�ش��������ǽṹ�����ݡ�Χ�����ݼӹ���ȫ�������ڣ�����֤ȯ�ۺ�Ӧ��OCR��NLP��RPA���������桢֪ʶͼ��AI ������
�ڷǽṹ������ʶ���������Ȼ����������ṹ���������ǽṹ��֪ʶ�洢������ȷ��棬��չ��˾���ǽṹ�����ݴ���ƽ̨���衣
һ���ǽṹ�����ݴ�������
������ҵ���ֻ�ת�͵ij������룬֤ȯ��˾�ڿͻ�������ڲ���������Ҫ���ӿ����Ч�ش������ֺ������ݡ�ͳ�Ʊ�������ҵ������80%
���϶����Էǽṹ������ʽ���ڣ���ռ�Ȼ��ڳ�������ǰ������֤ȯ�ǽṹ�����ݴ��������dz�������������������ҵ���ţ�����˾���е�ϵͳ��Ҫ��Խṹ�����ݴ��������轨��������������ھ�ǽṹ�����ݵļ���ƽ̨���Ӻ����������ھ��ֵ��
�ǽṹ�����ݼӹ�����ȫ�������ڿɻ���Ϊ���ֻ����ṹ����֪ʶ����ҵ��Ӧ���ĸ��Σ�������Ҫ������¹ؼ����⡣
1. �����ֻ��Σ���Ҫʵ�ֺ������ʽ�ĵ������ֻ�
�ĵ���Ϊ֤ȯ��˾ʹ�����ķǽṹ�����ݸ�ʽ���ص�����������ʽ���ࡢ���ݶ�����רҵ�Ժ�ʱЧ��ǿ������֤ȯ�������ĵ�ʶ�������������ȱ��ͳһƽ̨֧�֣��������˹����������Ľϸ�ʱ��ɱ����������ʽ�ĵ������ֻ�������Ҫ�漰�������ݣ���ɨ��PDF
��ͼƬ������OCR
ʶ��������ֻ����Բ�ͬ�����ļ�����ȫ��ʶ��ģ��ʶ�𡢱���ʶ��ȷ�������;�Կ���ȡ�����ĵ�����ȫ�Ľ���������˫��PDF��DOC/DOCX��PPT/PPTX��XLS/XLSX
�ȳ�����ʽ;�����ĵ���ʽ�������ߣ��������⡢���䡢ͼ����Ҫ�ؼ�λ�ã���������Ԥ����
2. �ڽṹ���Σ�ʵ����Ȼ���ԵĽṹ������������
֤ȯ��˾�ǽṹ�����ݵ�������Ҫ����Ȼ���ԡ���������岻ͬ����Ȼ���Ծ��ж����Ժ������ԣ�Ӧ������Ҫ�ӷǽṹ���ı��У���ȡ���ֽṹ����Ϣ���������ı������塣����֤ȯ��Ҫ��ע����������һ�ǻ�������ʵ��ʶ�𡢹�ϵ��ȡ�����Գ�ȡ���ı������NLP�㷨����ȡʵ�塢��ϵ�����ԡ����Ƚṹ����Ϣ;���ǻ�����������ʾѧϰ�����㵥�ʡ����ӡ����µȵ�����������ʾ���Ӷ��������������ԡ�
3. ��֪ʶ���Σ�ʵ�ַǽṹ��֪ʶ�Ĵ洢�����
����֤ȯ����������Էǽṹ��֪ʶ���й�����һ���ṩ�ǽṹ�����ݵ�ͳһ�洢��Ȩ���ƹ���;���ǻ����������漼�����Թ�˾�б��������ƶȡ������ĵ�����Ҫ�ǽṹ��֪ʶ�Զ�����������������֧�ֹؼ���ȫ�������⣬���������Զ�ժҪ�������ȡ����з���������ģ�������ȹ���;���ǻ��ڳ�ȡ��ʵ�塢��ϵ�����Թ���֪ʶͼ�ף��ر�����Ԫ���ݹ��������£��з����ѪԵͼ�IJ�ѯ��չʾ���ܡ�
4. ��ҵ��Ӧ�ýΣ��ڸ���������ʵ��Ӧ�÷ǽṹ�����ݴ���
��ҵ��Ӧ���У��ܶ�ǽṹ�����ݴ���������Ƕ�ڼ��и��������еģ�����ͬ�������̹�������������ϡ�Ϊ�ˣ���Ҫ��չ������RPA ���̣�������RPA
���õĽű���API �ӿڣ���OCR��NLP ��AI ��������ںϵ����̻����У���ǿ�桰RPA+AI�������������Զ������̹�������Ҫ̽����
�����ǽṹ�����ݴ���ƽ̨��ϵ�ܹ�
2020 �꣬����֤ȯ��չ�ǽṹ�����ݴ���ƽ̨���裬
�����ĵ����ܡ�֪ʶ���������ݹ�����������Ӧ��ϵͳ��Ϊ��˾�Ƹ��������ʲ����������㡢���Ϲ桢��ء�֤ȯ���ڡ���ӪͶ�ʡ�������ۡ���Ϣ������ʮ��������ṩ������ʵ���˷���ȫ��˾�ǽṹ�����ݴ�����Ը������ȡ������������Ч������Ч�档����֤ȯ�ۺ�Ӧ��AI
�����˹������ǽṹ�����ݣ�ʵ���˽�����Ч��Ŀǰ�ѽ�ʡ�ɱ�������Ԫ;�����˶��ַǽṹ��֪ʶ��ͳһ����ϵͳ�����ṩǿ���֪ʶ�������������������ܣ�����ͻ���Ա���IJ�ͬ����;�з�����ͨ�õķǽṹ�����ݴ������ܣ���ָ�����ҵ���ֻ�ת�͡�
���ݷǽṹ�����ݼӹ�������������֤ȯ�ǽṹ�����ݴ���ƽ̨��ϵ�ܹ����������ĸ����ܲ�(��ͼ1 ��ʾ)��
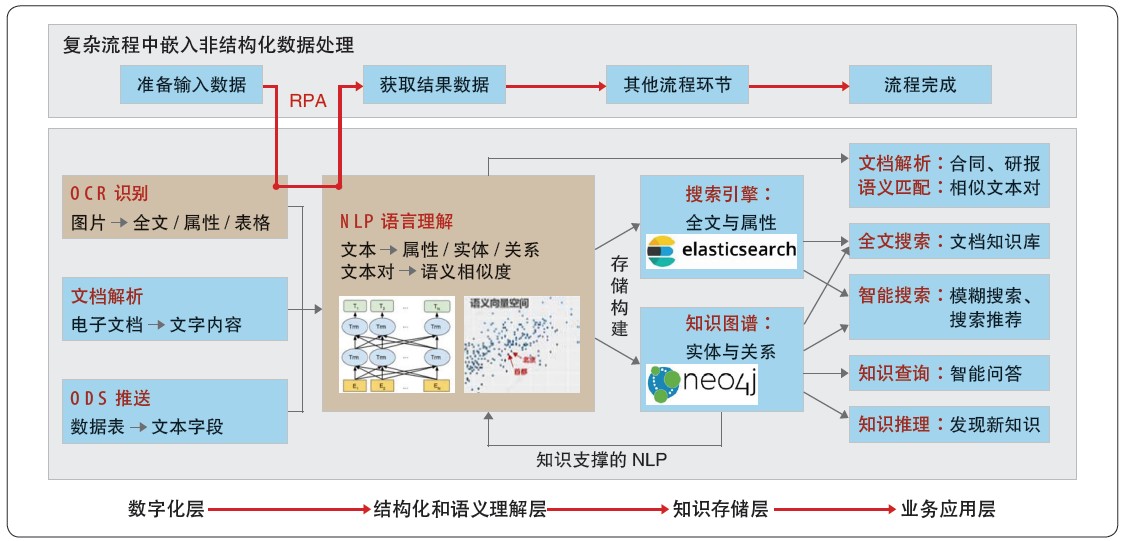
ͼ1 ����֤ȯ�ǽṹ�����ݴ���ƽ̨��ϵ�ܹ�
���ֻ��㣺������ֻ��Ǻ������ݴ����Ļ�������Ҫ�ǻ���OCR
ʶ������ȷʶ�����ɨ���ĵ������֡������ֵ���Ϣ;���⣬�������ǽṹ�����ݵ��Զ����͡������ĵ���������ع��ܡ�
�ṹ������������㣺��ע�ǽṹ��������ṹ����Ϣ��ת����ʹ�ø���NLP ��������ȡ�����ı��ṹ����Ϣ(ʵ�塢���ԡ���ϵ��)�����ⵥ��/ ����/
�ĵ��ȵ����岢�����������ƶȡ�
֪ʶ�洢�㣺�ӷǽṹ����������ȡ֪ʶ����֪ʶ������Ч�����ͼ��������������ҵ֪ʶ�⡣ʹ���������漼����֪ʶͼ������ǰ���ʺϴ洢���ı�֪ʶ֧��ȫ������;��������ͼ�״洢֪ʶ��֧�ֶ�ͼ���ݵ�����ѯ����㡣
ҵ��Ӧ�ò㣺�ڸ���ҵ��������Ӧ�÷ǽṹ�����ݴ����������ۺ�����ǰ���㴦�����������ݽ������ҵ��ϵͳ�������û�����;��Ը��������еķǽṹ�����ݴ������з�����ں�OCR��NLP
��AI ��������ǿ��RPA ���̡�
����ƽ̨֧�ŵ��Ͱ�������
���ڷǽṹ�����ݴ���ƽ̨������֧�ţ�����֤ȯΪ�����ҵ���������ѳɹ��з�ʮ����ǽṹ�����ݽ�������������ص�����ĸ����Ͱ�����
1. �з�֤ȯҵ���������ʶ������Ч�ʼ��ɿ���
�ںܶ�֤ȯҵ���У���Ҫ��������ֽ�ʱ�������ɽ����µ���������ˡ���Ʒ��ֵ����Ӫͳ�Ƶ�����ͨ������ȷʶ�����ɨ�������ͼƬ��Ϣ���ֻ����ܹ���������ҵ��ִ�е�Ч�ʼ��ɿ��ԡ�����֤ȯ�ڱ�������ʶ���������������̽���������ü���Ӧ�����ʲ�����������֤ȯ���ڡ����㡢��ӪͶ�ʵȶ�����š����ʲ�����������ʶ��Ϊ����ʵ�ֹ������ص�����������������ļ�����ս��
һ��ģ����༰��ģ�巢�֡���ͬ�ʹܿͻ���ʹ�ö���ģ��������������Щ�����������һ����������ܹ���ȷ������������ģ������ж���������ģ�壬���������ض�ģ��֪ʶ����Ƹ�Ϊȷ�ɿ���ʶ��ģ�͡����ڶ�ģ̬���ѧϰģ�ͣ����һ��ģ����༰��ģ�巢��ģ��(��ͼ2
��ʾ)��ģ���ۺ����ñ������ı���Ϣ����ҵ�ձ�(Logo)��Ϣ�����沼����Ϣ��Ԥ��ģ�����͡������ı���Ϣ����Ҫ���DZ��ⲿ������(�����п��ܰ�����ҵ���ƻ��ض��ôʱ����жϹ���ģ��)ͨ��Transformer
ģ�ͱ��룬�õ��ı���������ʾ����ҵ�ձ���Ϣ�ǵ��͵�ͼƬ��Ϣ�����ڼ�����Ӿ��е�VGG
ģ��ǿ���ͼ��������ȡ�������õ��ձ��������ʾ��������Ϣ��Ҫ����ת�������������ű�����ͬ�İ�������(���⡢������˵�����ձꡢ�հ�)�����ֵ�ɫ���룬�Ӷ���������Ϣת��Ϊ��ɫ��ϵ�ͼƬ�����ü�CNN
���缴����Ч��ȡ�����б��Ե�������ģ�Ͷ��ı����ձꡢ������������Ϣ��������ʾ�����ں�ƴ�ӣ����ͨ��ȫ���Ӳ�(softmax)���������շ�����(��ģ�嵥����Ϊһ��)��
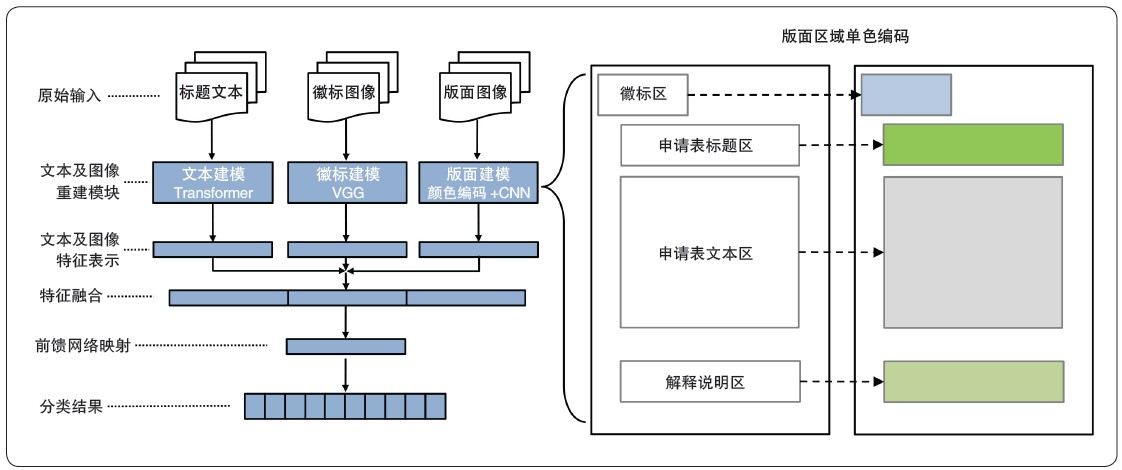
ͼ2 ģ����༰��ģ�巢�ֵĶ�ģ̬���ѧϰģ��
���ǻ��ڶ�ģ̬��Ϣ������ʶ�𡣶���ÿ��ģ��Ľ�����ȷʶ��ؼ��µ�������Ϣ���ۺ������ı����ݡ����ּ���Ԫ�����ꡢ��ɫ���䡢�ֺ�������ȶ�ģ̬��Ϣ���Խ����еĶ�����Խ���ͳһ��ȡ��������ù�˾��������ʷ�����������з�����ʶ���㷨��һ�����Զ������˺ܶ��б��ԺܸߵĹ���ģ�壬�Դ����ʵ��ֱ�Ӽ�������;��һ����ѵ�����ѧϰģ�ͣ��Թ����ܸ��ǵ�����������������Ԥ������Ŀǰ��ʶ��ȷ�ʺ��ǶȾ��ﵽ95%
���ϡ����ڽ����Կͻ�����ġ���������ʶ��ȷ��Ҫ�ߣ�����֤ȯ�з��˽��������˹��ܣ�����Ա��������������Ϣ�ͽ���ԭ���Ķ�Ӧ��ϵ���ṩ������ϵԤ�����쳣ȡֵ��ΧԤ���Ȼ��ƣ���Ŀ��ʾ���ܵ�ʶ������������ʶ������������ȷ�Ͻ��������ֱ�ӶԽӽ���ϵͳ������ʶ����˹��������������Ѿ������˽�������뵥��ÿ������ʱ��Ӽ��������̵�ʮ�����ӣ�����������Ч�ʣ��������˵��ͻ������������ύ���������ȫ����ʱ�µ��IJ������ա�
2. �з�CRM �����������֣������ƶ����û�����
�ͻ���ϵ����(CRM)ϵͳ��֤ȯ��˾�����ͻ���Ϣ��ϵ����Ҫϵͳ���ṩ�ͻ�ҵ��ȫ������Ա������֧������Ӫָ��ͳ�ơ����ⲿ�̻���Ѷ�ռ���ַ��Ⱥ��Ĺ��ܣ������ͻ��������������ͻ������ֵ��Ϊ֧���ƶ������µĿͻ���������֤ȯ�з����ƶ���CRM�������ֻ���Ļ��ʾ�����롢�����ȵľ����ԣ����PC
�ˣ��ƶ���CRM ���˻������������ٸ�����ս�����磬CRM
�ṩ�Ĺ��ܷ����Ҳ�θ��ӣ��û��ƶ����������Կ��ٶ�λ����;��������������ʵʱ��ѯ����ͳ��ָ��;�ͻ�ɸѡ������Ҫ���ڶ��ǩ�����Թ���Ŀ��ͻ����ƶ�����ɸѡ�����鲻�ѡ�
ΪӦ��������ս�������������������ԣ�ͨ������ʶ����Ȼ���Դ����ȼ���������֤ȯ�з��������������ֹ���(��ͼ3 ��ʾ)�������伯�ɵ��ƶ���CRM
��Ʒ�У������������û����顣����ʵ���У��������������ۺ����������¶���NLP ������
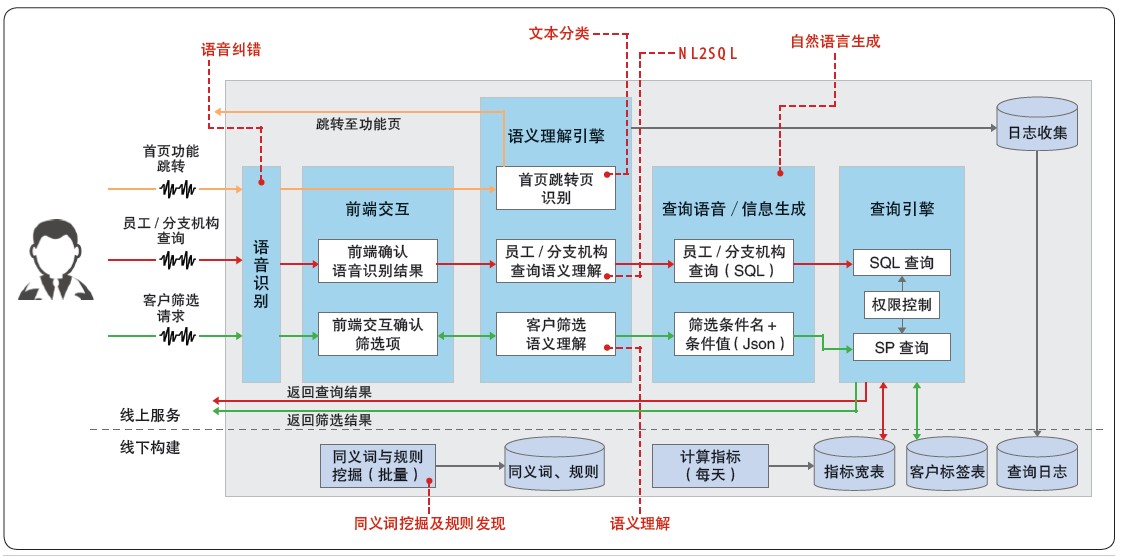
ͼ3 ����֤ȯCRM �����������ֹ��ܼܹ�
�����������������������Եȵ��µ�����ʶ��������Զ�������
�ı����ࣺʶ���û����ﻯ�����ϣ����ת�Ĺ���ҳ�档
�������⣺�����û��ĸ��ֿͻ�ɸѡ��������ȡ�������Ƽ�����ֵ��
NL2SQL��������Ȼ���Ե�ָ���ѯ����ת��ΪSQL ������в�ѯ��
��Ȼ�������ɣ������ֽṹ��ϵͳ��ѯ���������ǡ������Ȼ���Ա��
ͬ����ھ����û���־������֪ʶ���ھ�����ƵĿ��ﻯͬ��ʡ�
�����������ֶ��ƶ��˽���ʹ����ṩǿ�����Ľ���������Կͻ�ɸѡΪ���������������⣬���û��������Ŀ������룬ȷ�ж�ɸѡ���������ƻ�ȡֵ�����ǰ�˲����������/
��/ ɾ��ɸѡ����������ȷ����Ŀ���ѯ�����
3. �з���ҵ�ǽṹ���ĵ�֪ʶ�⣬�ṩͳһ֪ʶ����
��֤ȯ��˾��ҵ���ŵ��ճ������У������ĵ�����(�о����桢�걨/ �Ʊ�����������ƶȡ�����ҵ���ʴ�֪ʶ��IT
�����ĵ���)���ϲ������������ͷḻ����ҵ�ǽṹ��֪ʶԴ����Щ�ĵ������а��������м�ֵ֪ʶ��������ȱ��ͳһ�������洢����ѯ���������ߣ������չ��֪ʶ���ݵļ�ֵ������Ŀ�ۺ������ĵ������������������桢��Ȼ���Դ��������ݿ��ӻ����Ƚ��������Ե����ĵ������з�ͳһ֪ʶ����ϵͳ��Ϊ����ҵ���ṩ֪ʶ�������ľ����������֪ʶ�⣺
(1)�б�֪ʶ�⡣ȯ���б����о�Աд����֤ȯ��˾ӵ�е���Ҫ֪ʶ�ʲ����б���ΪPDF
�ļ���ͬһ��֤ȯ��˾��ȯ���б������ݺ�ʽ���Ͼ��й����ԣ�ͨ�������б��������ߣ��ܹ�ȷ����������ϸ���Ƚṹ���������⡢������ġ�����ͼ��;�����������н������Ĺ۵㡢���շ�����Ͷ�ʽ���ȳ������䣬
���ҽ�����ͼ�����Ķ��佨����������ȷ�����б�ϸ����֪ʶ�����ϣ����б�ȫ�ļ����ָ�����Ϣ����ȫ���������ܹ����ܼ������������ȫ�����ݲ�����λ��ԭ�Ķ��䣬ͨ���������Ƽ��㼰��������ͬ��ʻ��ܹ������������Ƶ��б����䡣���б�ȫ���������ھ��м�ֵ����ϢҲ�DZ������ص��ע�����⣬����NLP
�ؼ�����ȡģ�ͼ���ÿƪ�б��ؼ��ʣ�ͨ�������ȶȴ���㷨���Ը���ʱ��߶��µ��б����Ϲ������Ż���ʲ�ͨ�����ƿ��ӻ�չ�֣�ʹ���Ա��ͨ������ȴʼ��ɻ�ȡ�м�ֵ����Ѷ��
(2)�����ƶ�֪ʶ�⡣�����ƶȹ����ǹ�˾�Ϲ湤������Ҫ��ɲ��֡���������ƶȹ����д��ڵ����⣬����֤ȯ�����˹����ƶ�ȫ�������ڹ���ϵͳ��Ϊȫ��˾�ṩ�����ƶ�֪ʶ�⡣��ϵͳ�������������ƣ����ȣ�
�ƶ�֪ʶ��ͨ����OA
ϵͳ����ȼ��ɣ�ȷ�����ƶȷ������������������£����ֽϸߵ�����ʱЧ��;��Σ���Թ����ƶ���ʷ�汾�������з����ƶ��ĵ���ƥ��ͱȶԹ��ܣ��ھ�ͬһ�ƶȵIJ�ͬ�汾�������ݣ�ȷ���ƶ���Ϣ��¼ȫ����;������ƶ���Ϣ�������棬
֧�ְ�����ȫ�ļ����Ͱ���𡢲��ŵȱ�ǩ���ˣ�ͨ���û�������־�ͻ������ⲿ��Ϣ����רҵ�ʻ��ھ�ͬ������Ӷ�֧��ģ������������������Ƽ���Ϊ�û��ṩ��ݺ����ܵļ�������
���⣬֪ʶ����ϵͳ���ֱ���Դ�Ȩ��Լ�����ĵ����ϡ�ҵ�����ӪFAQ ֪ʶ��IT
�����ĵ��ȷǽṹ�����ݽ�����֪ʶ�⣬�������ṹ��֪ʶ���ճ�����������ϵ������
4. ������ҵ������ѪԵͼ�ף�����˾��������
����֤ȯ���м�������Ϣϵͳ�������ڹ�˾����ҵ������������Щϵͳ�������칹�Ծ���ϵͳ֮����ڸ��ӵ�����������ϵ��֤�����2018
��䲼�ˡ�֤ȯ����Ӫ������Ϣ���������취������ȷҪ����ػ����轨����ȫ����ȫ�������ڹ������ƣ���ʵ����������������ְ�𣬲�����������ʹ�ü�ֵ;����֤ȯ�ڲ�Ҳ�����ˡ��������������취����������������ʵʩϸ������������������������Ϊ��˾��Ҫ�Ĺ����������ݡ�
Ԫ���ݼ�����ѪԵ������������������Ҫ��ɲ��֡�����˵��Ԫ���ݾ��ǡ��������ݵ����ݡ�����ϵͳ�������ݱ������ֶ����ȣ��ܹ����ﲻͬ�����µ����ݶ���;
����ѪԵ�ܹ��̻�Ԫ����֮��ĸ���������ϵ��ͨ����Դ��ѯ��Ӱ���ѯ�ȷ����ֶΣ�����������������˾�ڲ���ϵͳ��Ԫ���ݼ���ѪԵ��ϵ�������˸��ӵ�ͼ���ݽṹ����һ����͵ķǽṹ�����ݣ�ʹ�ù�ϵ�����ݿ�������Ч֧��ѪԵ����������������֪ʶͼ����������н�ģ����Ԫ������Ϊ�ڵ㣬��ֱ�ӹ�����ϵ��Ϊ�ߣ����ø���ͼ������ھ��㷨ʵ��ѪԵ�������⡣
����֤ȯ����������ʽ������ҵ������ѪԵͼ�ף���Ҫ�ɷ�Ϊ���ࣺ��һ���ǵ���IT
ϵͳ�ڲ���ѪԵ��ϵͼ�ף��ڶ����Ƕ��ϵͳ֮��ѪԵ��ϵͼ�ס���ϵͳѪԵͼ�����ĺ��ļ�����SQL �������Ӷ������ݿ��SQL
����м�������ݱ����ֶε�ѪԵ��ϵ��Ŀǰ����Լ�ܱ��͡����չ�����֤ȯ���ڡ��ͻ�ָ���ȶ��ϵͳ������ϵͳѪԵͼ�ס����⣬����֤ȯȫ��˾��Χ��200 ����IT
ϵͳͨ��������ƽ̨ODS �Ȼ�����ʩ���ϴ������ݣ�������һ������ĸ�������(��ͼ4
��ʾ)������ϵͳѪԵͼ���跽���ɹ��ƹ㵽��ϵͳ��ѪԵͼ�����У�������ϵͳ��ϵͳ��ϵͳ�����ݱ������ݱ������ݱ���ѪԵ��ϵ�����ö�ϵͳѪԵͼ�ף����Բ�ѯij��ϵͳ�����ݱ��Լ�Ӱ������ϵͳ��������ݱ�����Դͷ���ݱ������仯ʱ����������Ӱ��ϵͳ�Ĺ���Ա����ʱ�������ݹ�����

ͼ4 ��ϵͳ��ѪԵͼ��Ӱ���ѯ����ʾ��
�ġ�������
����֤ȯΧ�ƺ����ǽṹ������ȫ�������ڴ����������ۺ�Ӧ�ö����˹����ܺʹ����ݼ����������˹�˾���ǽṹ�����ݴ���ƽ̨��Ŀǰ����ƽ̨�ѳɹ�����˾������ţ�ʵ����������Լ�ɱ�������Ч�ʵ�Ԥ��Ч��;ͬʱ��������ͨ�ñ���ʶ���ı���Ϣ��ȡ���������ƥ�䡢��ҵ֪ʶ�������桢����ѪԵͼ�������ѯ�ȶ���ͨ������������֤ȯ�ǽṹ�����ݴ���ƽ̨������֤ȯҵ���ֻ�ת�͵�һ������̽�������нϸߵ���ҵ�ƹ��ֵ��
|