|
分布式核心系统基础设施资源监控体系设计与探索
来源:中国金融电脑 作者:商婧 贾卓 日期:2024/7/19
文|中国农业银行数据中心 商婧 贾卓
摘 要:伴随国有大型商业银行由“集中+
开放”的融合式架构全面转向基于开放的分布式架构,保障监控系统面临的可用性和有效性挑战愈发凸显。对此,本文提出一种监测分布式架构下基础设施资源监控系统可用性和有效性的设计方案,并以此探索分布式核心系统的基础设施资源监控场景,总结了其在运维实践中推广落地的可行路径。
关键词:分布式核心系统;基础设施资源;运维监控;自动化监测脚本
数字时代背景下,伴随金融服务快速向线上化、数据化、智能化、开放化发展演进,银行业传统的集中式架构迎来了巨大挑战。为此,国有大型商业银行纷纷开启分布式架构转型,推动“集中式架构+
开放平台”的融合式架构全面转向安全可控的分布式架构体系。然而,
面对规模庞大、架构复杂的分布式核心系统,不仅运维人员需应对基础设施资源监控场景多样化、监控对象数量快速增长等诸多变化,且商业银行对监控系统的可用性和有效性也提出了更高要求。对此,笔者团队从强化基础设施资源管控的角度出发,设计提出一种监测分布式架构下基础设施监控系统可用性的技术方案,并总结梳理了四种已经落地的分布式核心系统监控场景及其实现路径。
一、基础设施资源监控体系设计思路
1. 监控系统架构
分布式架构下,基础设施监控系统支持直接性能监控、第三方性能监控等多种监控接入方式,可实现基础设施告警的统一接收、管理及转发,并提供了监控策略、告警处理规则等系统功能,确保故障“及时发现、准确定位、快速处置”。基于上述设计,笔者团队面向分布式核心系统,重点研究了四种基础设施资源监控场景,并将其归纳为分布式系统Monitor
监控、分布式系统Agent 代理监控、分布式系统日志告警监控和分布式系统可用性监控等功能模块。分布式架构基础设施资源监控系统如图1 所示。
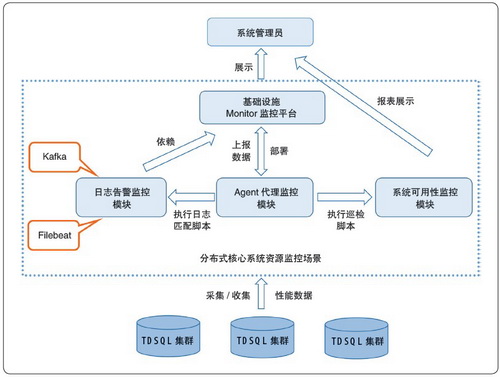
图1 分布式架构基础设施资源监控系统
具体而言,分布式架构下的Monitor 监控模块主要涉及直接性能监控,其通过在基础资源服务器上部署Agent
代理组件来执行所有本地监控脚本,并可采集监控对象的性能数据,在经过加工和处理后于平台页面中展示。该模块可监控分布式核心系统所有基础设施资源的性能数据,配置多种基础资源的性能监控策略和监控指标,并根据监控阈值规则对出现异常的监控对象发出告警信息。其中,Agent
代理组件的状态主要可分为在线和离线两种,离线状态意味着该节点服务器本地监控进程异常,无法执行下发到该机器的自动化脚本,同时也表明Monitor
监控模块无法采集分布式核心系统的性能数据,最终将出现Monitor 监控系统异常的情况。
对此,为更好满足对分布式核心系统的监控需求,
基础设施资源监控系统进一步引入了日志信息和系统可用性等第三方性能指标。例如,日志告警监控模块通过在数据库的节点服务器上部署日志采集组件Filebeat,
可监控指定的日志文件目录,收集并转发数据库和操作系统的日志数据,通过分布式发布订阅消息组件Kafka 发送至Monitor 监控模块,同时依靠Agent
本地监控脚本匹配日志文件的关键字,进行性能监控和告警。系统可用性监控则主要面向分布式核心系统日常巡检作业的执行情况,通过网关日志巡检、容量巡检、配置巡检、安全基线巡检等一系列操作,对分布式核心系统的可用性进行检查。上述监控场景同样依赖数据库节点服务器的Agent
代理来执行所有可用性巡检作业,并会定期将检查结果以报表的方式展示给系统管理员。
2. 可用性监测设计
针对上述四种监控场景,笔者团队基于监测和看护脚本的设计思路,分别设计了对应的可用性监测方案。
由于日志告警监控模块主要依托Filebeat、Kafka
等日志组件实现对数据库和操作系统日志信息的收集,因此,通过部署相应的守护进程脚本,配置本地服务器Crontab
定时任务,即可实时监控和看护组件的进程状态和可用性。同样,系统可用性监控模块通过Agent
来执行巡检作业,因此针对该模块需检查可用性巡检作业是否被正常执行、是否正常输出检查结果等。对此,笔者团队开发相应的自动化看护脚本,专门用于监测系统可用性巡检作业的执行情况。
此外,作为分布式基础设施资源监控系统的重要组件,实时监测Agent 代理的运行状态十分关键。为此,
笔者团队专门编写了自动化脚本每天监测数据库集群所有节点服务器Agent 的代理状态。在此基础上,对于展示Agent 监控数据的最终平台Monitor
监控模块,笔者团队通过设计看护脚本、配置定时任务来实时监测数据库组件和操作系统两类资源监控指标的运行状态,并选择根据Monitor
监控模块是否可以实时采集到监控对象的性能数据来判断其是否可用。
二、基础设施资源监控体系落地探索
1. 关键技术应用
监测Monitor 监控模块可用性的设计方案主要依托自动化脚本实现,该守护脚本实现的API
接口有三类,包括getLinuxReslnfo、getTdsqlResInfo 和 getMonitorResInfo。其中,getLinuxResInfo
和getTdsqlResInfo API
接口可分别从配置管理库获取操作系统基础资源监控对象和数据库组件监控对象的资源信息。两者首先以所属部门、投产状态和资源标签为输入参数,获取监控对象的资源ID
和主机名等两类属性信息,然后再以资源ID 为输入参数,通过getMonitorResInfo 接口从Monitor
监控模块获取监控对象的监控指标信息。以操作系统基础资源监控指标磁盘使用率system.disk.pct_usage 为例,其调用接口的自动化脚本如图2
所示。

图2 调用接口的自动化脚本示例
2. 可用性监测流程设计
在执行过程中,监测Monitor
监控模块可用性的技术方案主要包含三个部分,即获取监控对象的资源配置信息、监控性能数据和触发异常机制。其中,数据库组件类资源主要包括DATA 节点、GROUP
节点等资源类型,Linux 操作系统资源按照监控指标不同可分为“Linux 监控策略_标准”和“Linux 监控策略_通用”两类。以数据库组件和Linux
操作系统两类具有代表性的基础设施资源为例,监测Monitor 监控系统可用性的流程如图3 所示。
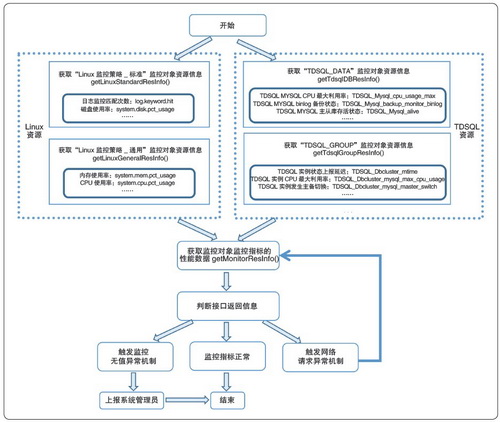
图3 监测Monitor 监控系统可用性的流程示意
在上述流程中, 首先根据getLinuxReslnfo、getTdsqlResInfoAPI
两类接口分别获取监控对象的资源信息,之后再调用getMonitorResInfo 接口获取该资源对象的监控指标数据,如DATA
节点资源的主从库存活状态、操作系统的CPU
使用率等。同时,为避免出现偶然的误监测事件,该方案采取多次查询和设置多个查询时间范围的方式,支持批量检测监控资源的全部监控指标,最后再根据接口返回信息判断Monitor
监控模块是否在正常运行。
在发生异常的情况下,Monitor
监控模块通常呈现出监控无值异常和网络请求异常两种状态。其中,监控无值异常即为该资源对象没有监控数据,表明系统对该监控对象失去联系,需立即触发监测异常机制,并通过邮件或短信的方式将检测出监控异常的资源对象信息发送给系统管理员进行人工处置。网络请求异常是指平台本身接收接口参数时触发的异常,通常是在看护脚本大批量调用接口查询资源信息时,因调用频率峰值过高引起,该异常会间隔一段时间再次调用接口,直至正常结束或触发监控无值异常。
三、结论与展望
综上所述,笔者团队设计了一种监测分布式架构下基础设施监控系统可用性的技术方案,并针对分布式核心系统探索归纳了四种监控场景,多维度覆盖分布式核心系统监控链路的关键指标,进一步丰富了分布式核心系统监控体系,对分布式数据库的应用推广具有积极意义;同时,通过基于监测与看护脚本的思想进行方案设计,高效确保了数据库基础设施资源监控体系的可用性,为分布式核心系统加固了运行保障。后续,笔者团队将进一步探索实现智能化监测的可行路径,在减少人工处置流程的基础上,尝试使用邮件通知来确认是否可以自动重启监控,进而持续提升监控全链路自动化、智能化水平,加速推动分布式核心系统可靠性能力向运维智能化演进。
参考文献:
[1] 王泳滨.农业银行信用卡分布式核心系统建设实践[J]. 中国金融电脑,2023(6).
[2] 徐建斌,顾佳倩.核心系统资源有效管理探索及研究[J]. 金融电子化,2021(10).
|