|
基于大模型智能体的授信调查报告生成应用研究
来源:《中国金融电脑》 作者: 日期:2026/1/7
作者:华夏银行 龚伟华 马树新 王彦博 杨潇 李璧鲁
龙盈智达(北京)科技有限公司 宫小奕
习近平总书记强调,谁能把握大数据、人工智能等新经济发展机遇,谁就把准了时代脉搏。华夏银行基于大模型智能体技术开展应用创新,自主研发了银行授信调查报告自动生成系统,实现了对公授信调查报告分钟级生成,为大模型智能体赋能金融业务发展提供借鉴。
一、业务背景与目标
对公授信调查报告历来是商业银行公司业务风险管理的第一道关口。传统经营模式下,客户经理需手工收集30多份材料,对年报、财报、评估报告、合同等文件进行摘录、比对、归纳与撰写,完成一份对公授信调查报告通常需耗时3~10天,若遇到股权结构复杂、跨区域资产抵(质)押等情况,报告撰写周期可能超过4周,难以满足实体经济短、频、急的融资需求。
在此背景下,将大模型智能体技术应用于授信调查报告自动生成场景,已成为各商业银行关注的焦点。华夏银行通过构建“4+11+4”的授信调查报告智能生成业务方案,即面向申请人、保证人、抵押人、质押人4类客户身份,针对上市公司披露报告(年报、季报等)、财报四表一注、抵质押物评估报告等11类非标文件开展智能解析,集成行业分析、智能财报分析、抵(质)押物分析、负面舆情分析4大核心功能,实现“一次上传、智能解析、统一填充、一键生成”,将对公一般授信调查报告撰写时间由天级缩短至分钟级。
在授信调查报告自动生成场景中,研发人员普遍面临金融信贷专业门槛高、需求分析立体化多元化、多源异构数据整合困难等诸多挑战。例如,授信调查报告中“应收账款占收入比例异常”背后,可能蕴含着收入确认政策、客户集中度、季节性波动等10余条风控规则,研发人员如果仅把这句话当作普通文本,模型则难以捕捉到异常的阈值和语义权重。资深审批人具备的丰富专业经验,本质上是大量隐式特征的非线性组合,因此需要业务专家把“感觉”翻译成“可计算”的规则与样本。没有业务专家的深度介入,再先进的算法模型也往往会在专业术语、隐性规则、监管变化面前迷失方向;同时,没有研发人员的工程化能力,再丰富的业务经验也难以规模化、标准化广泛应用。业技融合不是锦上添花,而是打破专业壁垒、跨越数字鸿沟、实现可信AI的双向奔赴。
针对上述挑战,华夏银行遵循全面质量管理“人―机―料―法―环”方法论,通过迭代50余版提示词、验证10余款基础大模型,以确保系统稳定输出、内容准确,打通业技融合的“最后一公里”。具体而言,一是在人员方面,组建了由总分支行专职审批人、客户经理、数据科学家、技术研发专家等组成的混合专家团队。二是在机器设备方面,聚焦AI算力资源的精细化管理,推进智能算力资源池化平台建设,通过构建动态资源分配机制并实时监控算力负载状态,实现计算资源的弹性伸缩与均衡分布,提升算力资源的使用效率和运营效能;引入以RoCE(RDMA over Converged Ethernet)技术为核心的高性能互联方案进行无损网络设计,通过优先级流控制、显式拥塞通知等技术,构建高带宽、低时延、支持大算力协同的网络环境,夯实AI网络架构技术底座。三是在数据算料方面,围绕数据获取、质量管控和有效利用,广泛接入并整合内外部多源异构数据,针对采集的数据制定“完整性、准确性、时效性、一致性”四大校验规则,构建数据算料动态迭代机制,持续优化数据资源池。四是在技术方法方面,提出“5M”方法论体系,采用多智能体(Multi-Agent)及模型上下文协议(Model Context Protocol,MCP)丰富应用内涵;通过知识管理(Management of Knowledge)解决通用RAG短板问题;采用多模态模型(Multimodal Model)及生成式与判别式AI融合(Mixture of Generative&Discriminative AI),解决该场景下普遍存在的模型识别瓶颈问题。五是在业务环境方面,构建以用户为中心、与业务流深度耦合的应用生态,确保技术成果能够顺畅转化为业务价值――首先打造基于自然语言的人机交互界面,通过自然语言实现用户与应用的双向沟通;其次构建持续演进的价值闭环,建立从业务一线直达技术研发团队的敏捷反馈与迭代机制,通过用户使用数据分析、满意度调研及业务成果量化,持续验证并优化系统对业务的实际贡献,形成“业务驱动创新、创新赋能业务”的良性循环。
二、方法论体系及关键技术
针对基于大模型智能体在授信调查报告生成过程中面临的技术难点,华夏银行创新提出的“5M”方法论体系涵盖多智能体、模型上下文协议、知识管理、多模态模型及生成式与判别式AI融合五大技术领域,从而解决各类技术难题。
1.多智能体技术
单智能体的决策逻辑依赖预设规则或静态数据,面对需求波动、突发故障等不确定场景时,易导致大模型在长链路信息交叉处理任务中出现算力瓶颈、信息孤岛及幻觉等问题。
针对单智能体的短板,华夏银行基于银行授信调查报告自动生成系统(如图1所示),通过构建“4A”智能体框架,将身份评估(Assessment)、文档分析(Analysis)、功能应用(Application)和报告组装(Assembling)4类智能体集成到统一调度框架,由对话缓存存储与向量存储高级检索组成的双记忆池协同工作,保证4类客户信息跨智能体不丢失,形成“读―析―写”闭环。
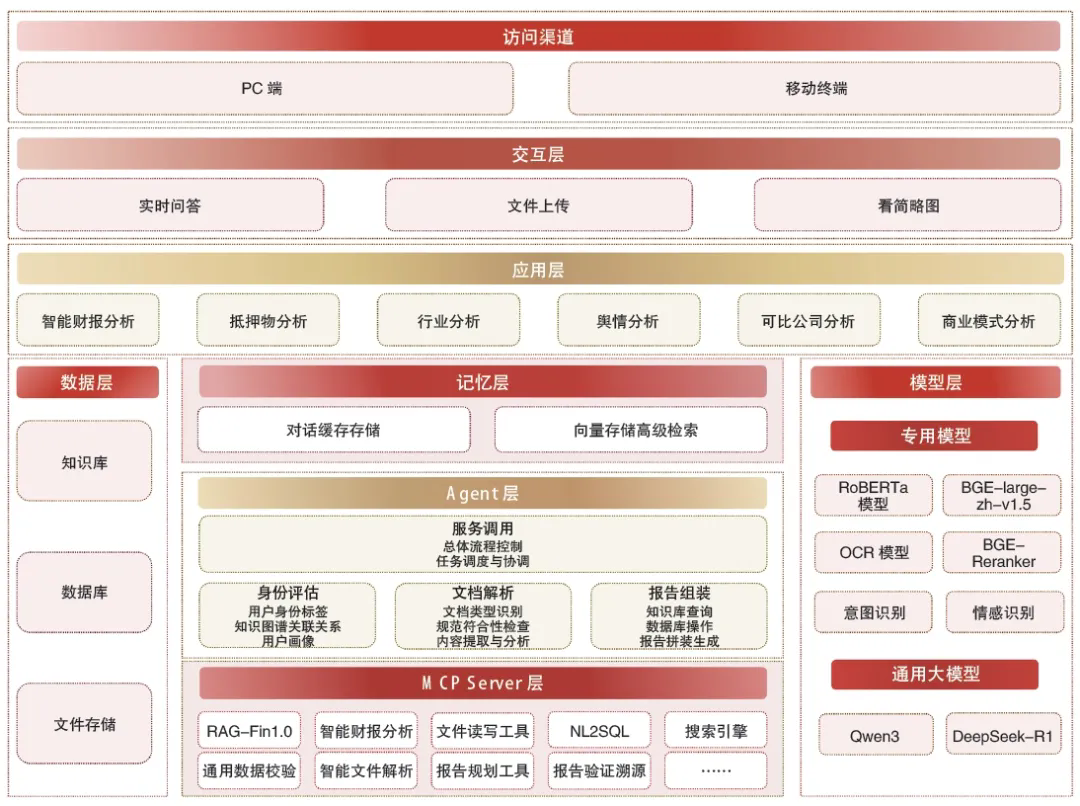
图1 银行授信调查报告自动生成系统应用架构
2.模型上下文协议技术
模型上下文协议技术旨在实现大模型与外部数据源、工具及服务的标准化集成,使AI模型从“文本生成器”进化成为能够主动执行任务、整合资源的“智能助手”。
华夏银行围绕业务分析工具(Business Analysis Tools)、RAG相关工具(RAG-related Tools)、引擎工具(Engine Tools)、AI辅助工具(AI-assistant Tools)和数据/文件处理工具(Data/File Processing Tools),构建了MCP BREAD框架,将智能财报分析、RAG-Fin1.0、搜索引擎、OCR、数据核验、文件解析、文件读写等能力封装为MCP Server工具,使任何能够发起HTTP请求或执行本地命令的应用都可以作为MCP Client端调用MCP Server。MCP Server的标准化接口方便跨平台应用,从而以统一、敏捷的方式调用服务端的AI能力,不仅可降低AI应用的开发门槛,还可避免重复开发。需要注意的是,在此过程中,对于智能财报分析此类高频、耗时的MCP Server工具需做好缓存、异步处理等;文件读写这类涉及数据权限的MCP Server工具需注意权限控制及安全性管控等。
3.知识管理技术
通用RAG在金融垂直领域通常存在召回噪声大、溯源链路丢失等问题。华夏银行构建了涵盖双路检索(Retrieval)、查询重写(Rewrite)、倒数排名融合(Reciprocal Rank Fusion,RRF)和重排序(Reranker)的4Re框架,实现RAG高并发、高精度召回。其中,双路检索是基于北京智源人工智能研究院开源文本向量嵌入(BAAI General Embedding,BGE)模型和最佳匹配25(Best Matching 25,BM25)模型实现的。此外,华夏银行为每个Chunk写入通用唯一识别码(Universally Unique Identifier,UUID),并注入“文件ID+来源段落+URL+时间戳”四要素信息,将通用RAG优化为RAG-Fin1.0。在基于大模型生成答案时,该框架不仅提升了查询质效,还实现了原文溯源定位。
4.多模态模型技术
对授信调查报告自动生成场景相关文本进行内容提取所涉及的内容包罗万象,而且标注样本稀缺,传统OCR技术难以完全覆盖。因此,华夏银行使用预训练视觉编码器将图片转换为数字特征,并与语言指令相结合作为大模型输入,利用图像本身具有的多标签语义信息,为现有无标签数据样本提供新的伪标签无监督标注方法,该方法不仅提高了特征表达能力,还为下游图文检索任务和分类任务提供基础。在此基础上,华夏银行结合上下文信息构建了多模态模型,并应用“5P”框架(如图2所示)进行内容提取,以支持高效的信息识别与处理。

图2 多模态模型内容提取的“5P”框架
5.生成式与判别式AI融合技术
跨页表格的信息自动提取是当前业界较难解决的问题,且在传统建模过程中,建模工程师的能力水平参差不齐,重复性工作较多。为此,华夏银行提出涵盖智能建模(Smart Modeling)、样本生成(Sample Generation)、监督微调(Supervised Fine-Tuning,SFT)、结构化标签(Structured Labels)的4S框架,以200份非标文件为样本数据,成功实现F1Score达到93%,财报附注等跨页表格完整提取率大幅提升,建模人力成本下降了60%。
遵循4S框架,华夏银行依托通用大模型,自动完成数据处理、特征工程、算法选择、指标评估等环节,结果显示RoBERTa模型在该场景下优于其他模型,实现了判别式AI智能建模;依托通用大模型批量生成1万条样本,用于微调RoBERTa模型,实现大模型辅助样本生成;运用LoRA技术微调RoBERTa模型,使模型的Accuracy和F1-score达到0.9673及0.9646,进一步对模型进行量子化改进,运用量子经典混合LoRA技术微调RoBERTa模型,使模型的Accuracy和F1-score提升至0.9744及0.9721,实现了监督微调;对微调后的RoBERTa模型基于生成样本与真实标注数据进行联合训练,精准识别每行文本的语义角色,实现结构化标签的输出。华夏银行深度融合生成式AI与判别式AI,引入上下文感知与语义连贯判断技术,有效实现了分页断句的智能拼接。
三、应用成效与价值
授信调查报告自动生成场景是提升贷前周期效率的加速器,是从经验决策向科学决策转变的导航器,也是解放客户经理双手、方便其将更多时间与精力投入到深度客户关系营销中的助推器。理性的信贷决策可以防止授信客户因不切实际的贷款需求而陷入债务困境,从而保护借款人的权益,促进金融安全稳定发展。
过往,对公客户经理手工撰写一份调查报告加权平均用时37.8小时,而基于以上技术自动生成一份报告用时在10分钟以内,内容覆盖率超70%,效率提升约200倍;同时沉淀了知识库资产,可助力加快重点领域信贷投放,培育壮大新的增长动能。以上技术不仅适用于对公授信调查报告自动生成场景,还可复用至普惠金融、产业数字金融、投资银行等业务条线,具备广泛应用推广价值,为大模型智能体赋能金融业务发展提供借鉴。
四、结语
面向商业银行普遍关注的授信调查报告自动生成场景,华夏银行提出了“4+11+4”的智能业务解决方案,助力信贷资源更快、更精准地流向优质企业,为稳定市场主体、激发经济活力提供了金融支撑;在技术层面提出“5M”方法论体系,为商业银行探索“AI+风控”“AI+客户服务”等更多场景提供了可复制的技术范式。华夏银行的探索与实践,以业技融合为内核,以“人―机―料―法―环”为路径,充分印证了商业银行数字化转型的核心规律:技术创新需扎根业务场景,以解决实际痛点为导向;业务升级需依托技术赋能,以数据驱动打破经验依赖。商业银行可通过组建跨领域专家团队、构建智能算力底座、建立数据管控机制、打造业务耦合生态,让AI技术由业务辅助工具进化为核心生产力。
未来,随着《国务院关于深入实施“人工智能+”行动的意见》等政策的深入推进,大模型智能体有望在金融风控、客户服务、合规管理等领域发挥更深层次的作用。商业银行需以业务需求为牵引、以技术创新为驱动、以服务实体经济为根本,在新一轮科技革命与产业变革中把握先机,构建“效率与风险并重、科技与人文共生”的现代金融服务体系,为金融高质量发展、经济转型升级贡献更大力量。
本文得到北京市科技计划“基于CoE架构的银行信贷风控大模型系统关键技术研究与应用”项目的支持,项目编号:Z241100001324024。
华夏银行姜慎威、陈大伟、杨雷、胡悦寒、俞博文、刘岩、王钦朋和连加俊,以及龙盈智达(北京)科技有限公司张月、杨璇和徐奇对本文亦有贡献。
文章转载自《中国金融电脑》2025年第12期
|